
All I wanted was to grok some real-time data
and how I ended up with a street PhD in Distributed Systems


Midjourney Prompt: painting in the style of dutch golden age. people looking at reams of real time data at the 17th century stock market.
Real-time databases and stream processing systems1 have at-least been around for 2 decades in various forms. While stream processing has increasingly become important especially with the rise of the Kafka ecosystem, it has still remained somewhat of a niche topic. Only to be tackled once the low hanging fruit has already been taken care of by hammering near real-timeness from your existing data architecture.
A Brief History of Real-time Systems
My personal journey with working with streaming data/real-time event processing started well over a decade ago when I worked in the bowels of a real-time bidding ad-network that saw non-trivial scale. And we’re talking about the days when being a “Hadoop Big Data Engineer” involved an unholy duct-tape of Pig scripts & bespoke Map-Reduce jobs orchestrated by Oozie over an over burdened YARN cluster.
A typically example of a workload in an ad networks is the CTR (click through rates) prediction pipeline. This computes CTR predictions on live ad campaigns while being able to make adjustments in real-time. Getting this prediction off usually meant losing real money. And to make sure, our CTR predictions were correct we ran the aforementioned pig-oozie-yarn job at 5 minute increments. This worked well… kinda sorta. This arrangement was still brittle as it wasn’t able to account for bursty traffic, and assuming that jobs did finish within the 5 minute window they were scheduled for, the generated data had a baked-in delay of anywhere between 5 to 10 minutes!
Enter Kafka + Storm
Moving to Kafka and Storm based architecture circa 2013, was a step change in what we were really able to do with our general purpose hardware. Kafka was a fairly extensive and well built event bus one could effortlessly emit events from disparate backend and user facing systems onto while Storm had a clear functional api to build our event driven pipelines to actually process that data as soon as it entered the Kafka topic. This truly felt like computing in the future.
The era of Spark & Flink
Storm was quickly followed by Spark Streaming and Flink in the mid-2010s. Spark Streaming, which was technically a microbatch framework,2 was built atop Spark’s massive success in the map-reduce batch data world while Flink was the most complete stream processing framework out there. It was capable of event time processing along with more traditional processing time. 3 It came with processing semantics such as at-least once as well as exactly once. 4 Knowing how to write a stateful streaming job correctly in Flink became a secret weapon in any self-respecting Data Engineer’s repertoire. Entire one off bespoke stateful services could be now replaced by a quick Kafka + Flink job.
It’s 2023 and Real-time Data is Still Hard
Given the sweep of developments in space over the last decade or so, one would have thought that building real-time data applications is now a breeze. Well you’d have thought wrong. The experience is still very much hot garbage. We discovered how hard it still really is for ourselves when we had to build an application late last year to ingest, process and serve gigabytes of data in real-time.
The current commonplace architecture for real-time systems looks something like this -
Ingestion Layer - data that is produced in async by disparate clients and services that needs to be centralized to a robust ingestion layer. Kafka is often the de facto choice in this department.
Processing Layer - applications with specific real-time transformation and data enrichment need or stateful computations need to add in a specific Spark Streaming or a Flink job for the purpose.
Querying Layer - all the real-time ingestion and processing capabilities of your system are for a naught if you don't have a robust querying layer to serve the data within reasonable freshness bounds as well as volume.
It took us a surprising amount of time to get basic bits of infrastructure such as Kafka, Spark and Clickhouse running. And despite trying multiple cloud vendors and “managed clouds” we still needed to glue these systems together for our end-to-end operation. This involved rolling out our own semantic layer to translate between Avro schemas for Kafka, Parquet for the Spark job and Clickhouse schemas for Clickhouse. Taking our app from prototype to production became a herculean effort.
Even after the basic pieces of infrastructure were stood up, the experience of writing stream processing applications felt surprisingly pre-modern. The feedback loop from writing data to a temporary Kafka stream, to writing a Flink application to process it and then indexing the data in a columnar store such as Clickhouse runs in days if not a week or two. With any changes in the application logic thereafter requiring developers to run through the long grueling cycle all over again.
After having tried a host of systems and accumulating scar tissues over a hundred paper cuts, here are some broad intuitions about our desired developer experience.
The semantic layer should be on autopilot
In the example system we underlined above, we needed to maintain three separate schemas (!). Avro for the data bus (Kafka), Parquet for the data lake and Clickhouse for the time series database. While some systems have their own schema registries, the translation between the preferred serialization formats of choice for these systems is often an exercise left for the implementer.
Converting something as basic as a Datetime Field across these different formats becomes a veritable game of telephone leading to subtle bugs in the application. Some (looking at your Confluent) even had their own versions of the popular formats that don’t work with standardized open source tooling.
Most of the schema registry/data catalog products we tried, relied on manually hand typed schemas. And then even if you were a boss engineer enough to hand type a yaml acceptable to the confluent schema registry, this still left out figuring out how to translate between the types available to the parquet and clickhouse portions of your pipeline and no way of being able to figure out sensible defaults.
Now don’t get me wrong, data types are an extremely subtle topic and correctly typed schemas can pay off a hundred fold depending on the database in question. That said, optimizing types off the bat and expecting a user to type out the ideal finalized schema before even being able to prototype an application feels a touch backwards.
In the idealized real-time platform of our hopes and dreams, we should simply be able to send a few example data points to the platform and let it figure out the schema. If I were a betting man, I would posit that for most of the tables ever created, a basic rule based schema inference would work just fine.
Tyranny of tuning too many knobs
To get even the most trivial types of stream processing applications running off the ground, you end up with 2 to 3 different distributed systems and their resulting operating parameters and knobs that now need to be a part of your mental model of the overall system. Oftentimes these systems don’t come with sensible defaults and no way to clearly reason about tuning them holistically for your use-case.
Short of just trying a bunch of experiments, one needs to know the arcana of classical distributed systems literature to even have a sense for rules of thumb for selecting defaults. And given that a lot of data toolchain runs atop the JVM, one needs to speak fluent JVM tuning to be able to truly run these systems fearlessly in production. That adds another layer of knobs to tune and reason about their interactions with the attendant system and keeps JVM consultants in business.
No one engineer can be realistically expected to be an expert in the dark arts of whispering to each of the systems that constitute your real-time pipeline.
Real-time is relative
Lastly, modern stream processing systems are built with the ability to sustain p99 use-cases in terms of scale and latency. Flink for instance, has extremely robust and customisable windowing and triggering API with ability to handle late coming data as well. The trade-off here comes in at the expense of developer experience and operational complexity involved in getting even the minimal of stream processing jobs up and running.
The definition of “real-time” is fairly relative and for most use-cases an end to end delay of a few seconds between ingestion, processing and indexing is fairly tolerable. Making the developer experience for these use-cases as smooth as possible would cover most of the use-cases people end up running separate Flink jobs for.
Introducing Denormalized
So if you have read thus far into this screed, dear reader, it is my pleasure to introduce Denormalized, a real-time data platform built with developer productivity in mind. We believe working with real-time data should be a straightforward and a painless experience. A developer should be able to go from prototype to production in a matter of minutes. We built Denormalized to address the pain points we underlined above.
Creating a Data Stream is really easy
Creating a new table in Denormalized is as simple as just sending it a few example rows and our PyArrow based inference takes care of the rest. This is what creating a new topic in denormalized looks like.
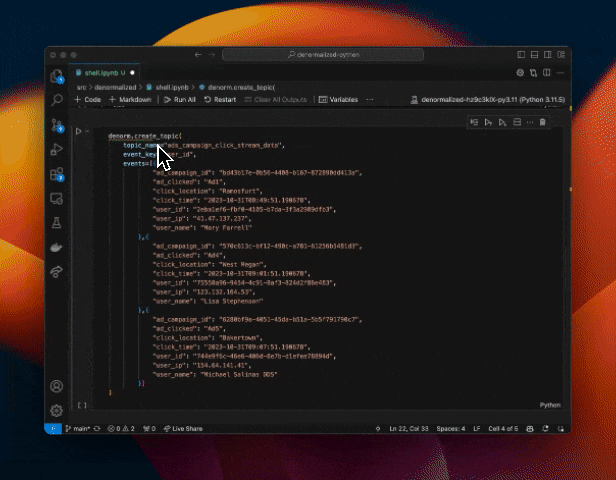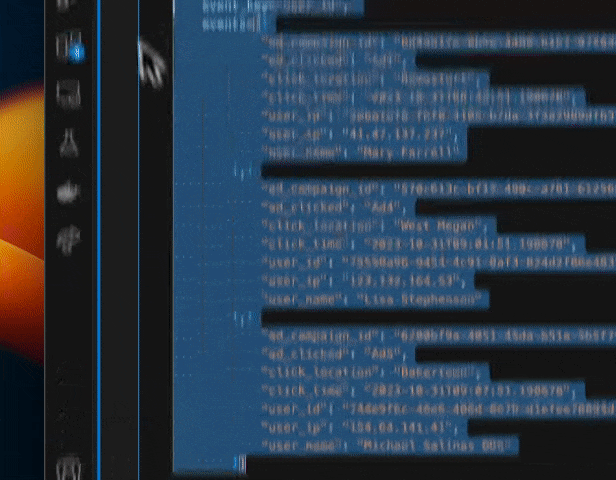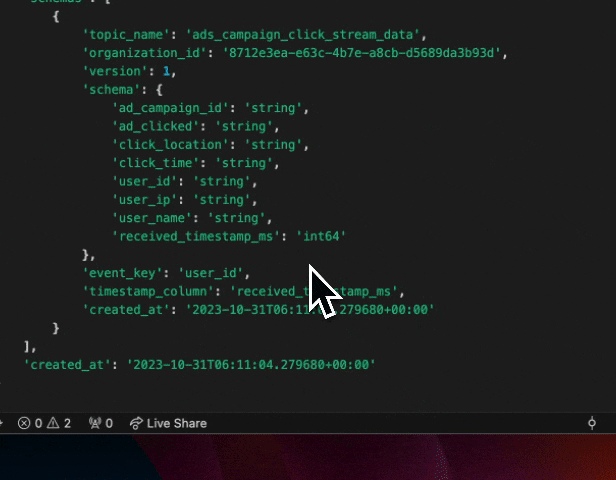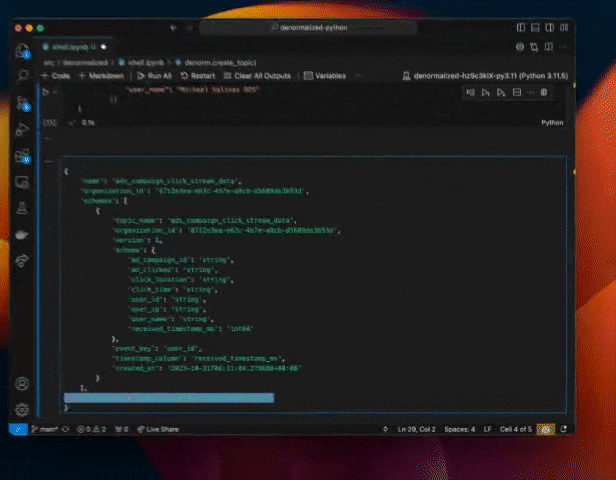
Effortlessly define simple data transforms without a Stream Processing System
Save the environment, run fewer JVMs. Just kidding. But seriously though, although we ♥️ Flink that Flink job could’ve been an ingestion time transform.
We have dozens of inbuilt transforms to work with string interpolation, arrays, nested json structures and many more. Run simple ETL on your columns in a stream without needing to write a separate Flink job for the same.
Run Complex Streaming SQL Queries
Go from prototype to full lightning fast time series queries in under a minute…
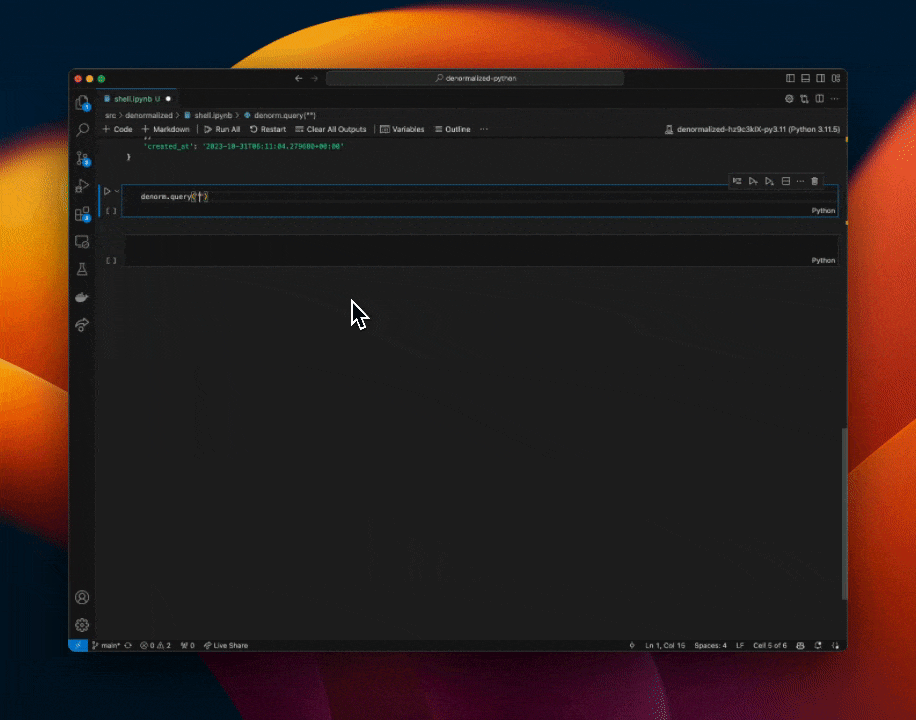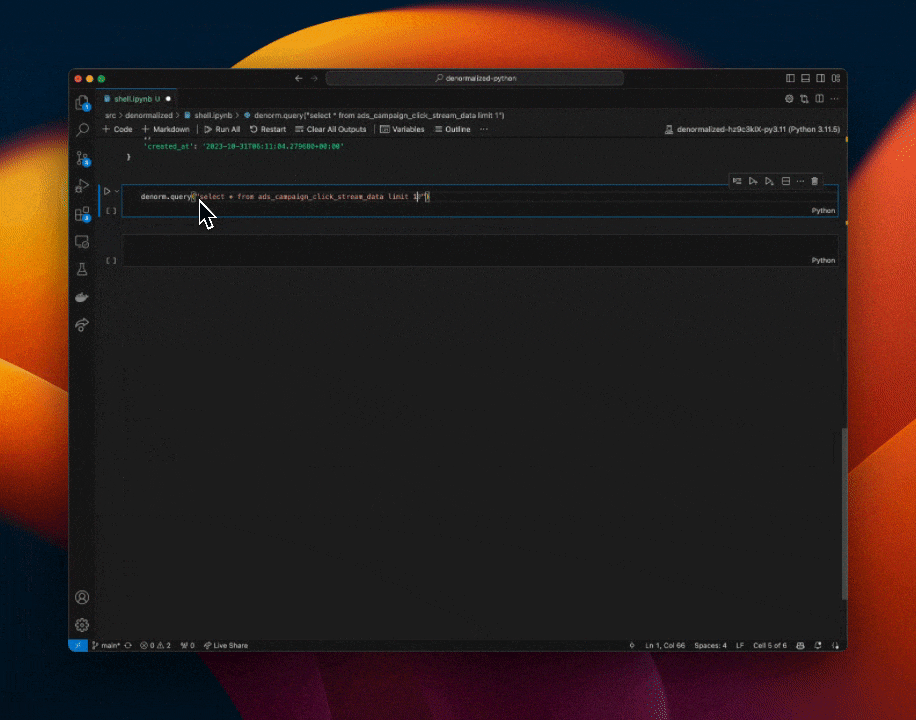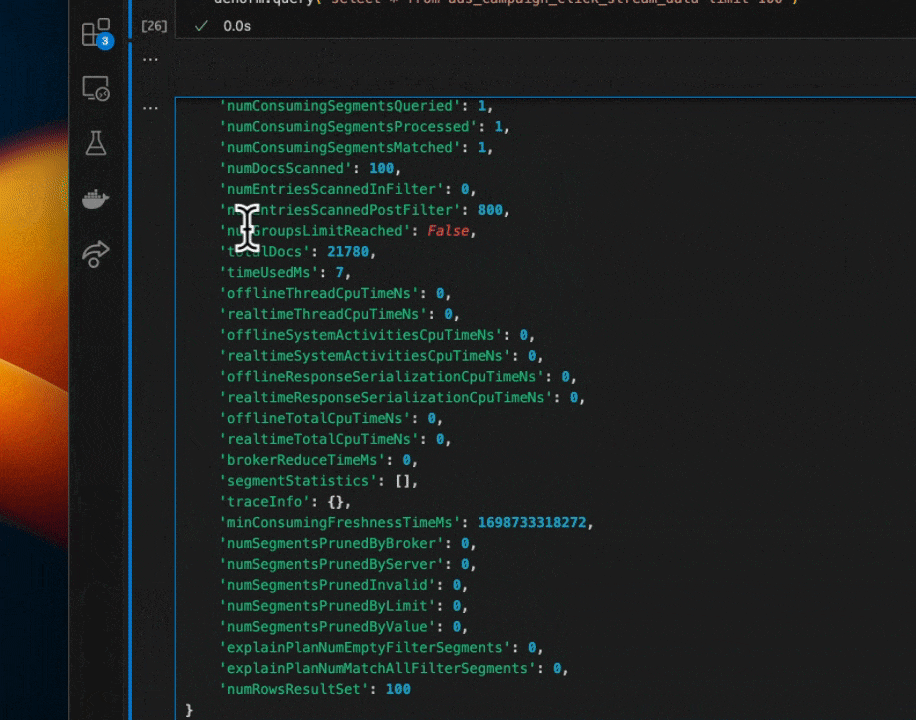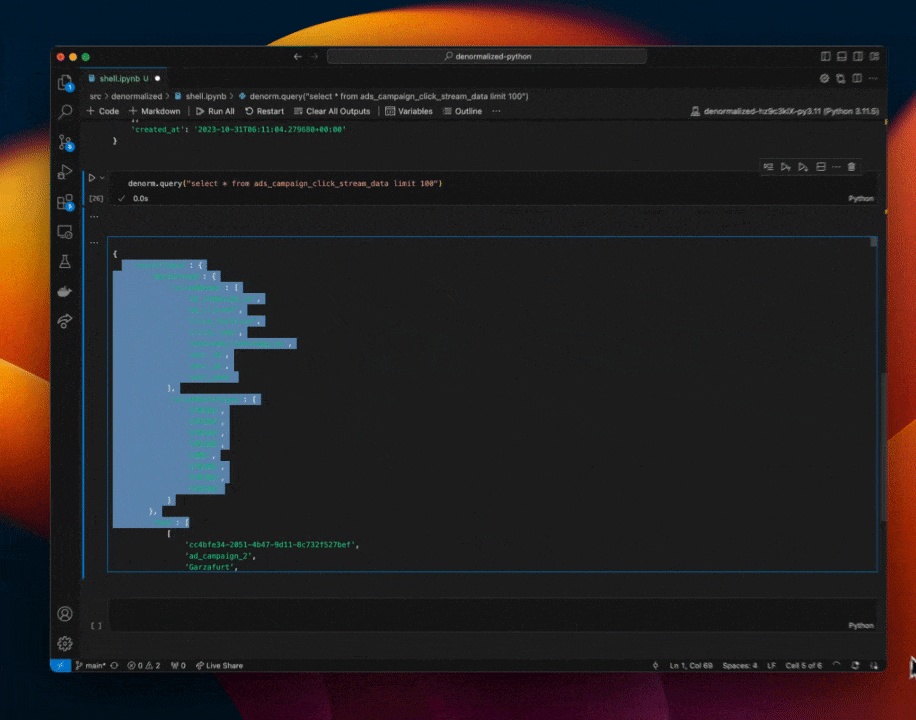
We are built atop Kafka + Pinot and are just getting started. Our goal is quite simple. Make working with real-time data not suck. If you’d like to get early access to our platform please reach out to: hello@denormalized.io